Abstract
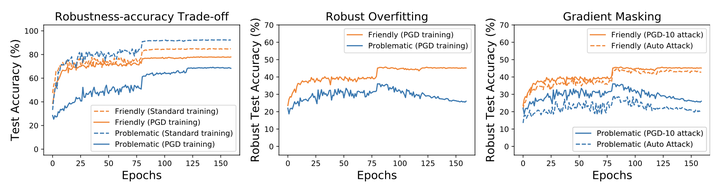
Multiple intriguing problems are hovering in adversarial training, including robust overfitting, robustness overestimation, and robustness-accuracy trade-off. These problems pose great challenges to both reliable evaluation and practical deployment. Here, we empirically show that these problems share one common cause – low-quality samples in the dataset. Specifically, we first propose a strategy to measure the data quality based on the learning behaviors of the data during adversarial training and find that low-quality data may not be useful and even detrimental to the adversarial robustness. We then design controlled experiments to investigate the interconnections between data quality and problems in adversarial training. We find that when low-quality data is removed, robust overfitting and robustness overestimation can be largely alleviated; and robustness-accuracy trade-off becomes less significant. These observations not only verify our intuition about data quality but may also open new opportunities to advance adversarial training.
Chengyu Dong
Curiosity and Enthusiasm